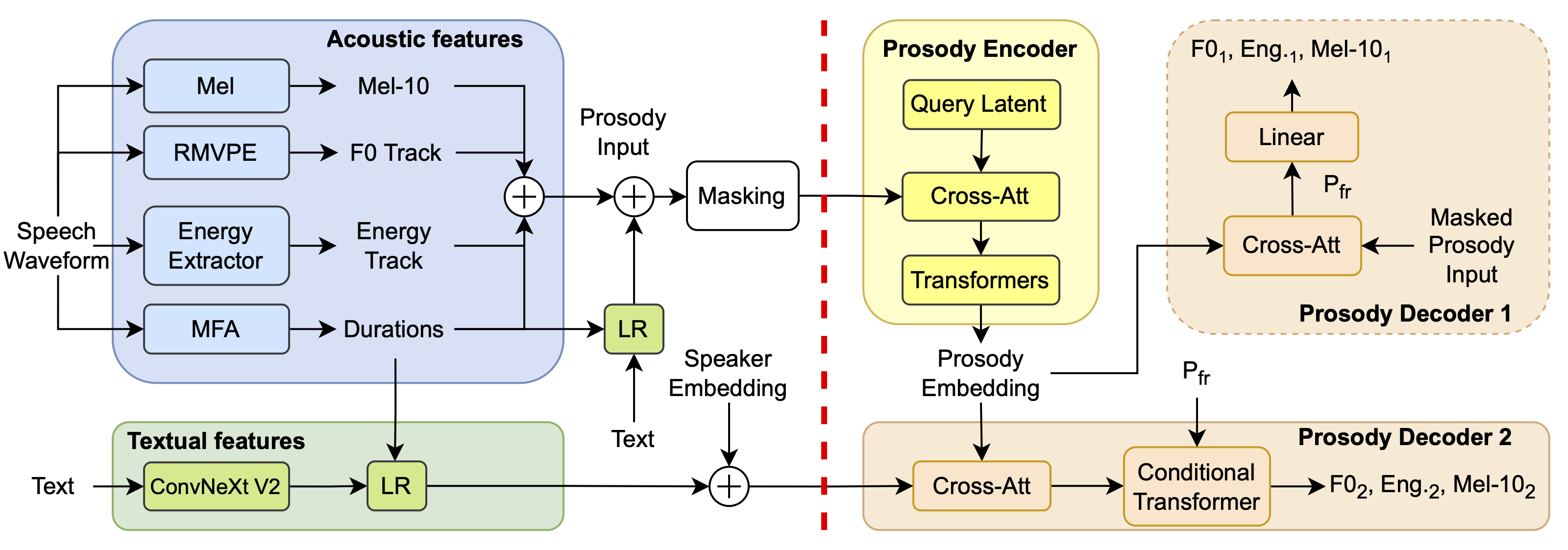
Figure 1: ProMode Diagram.
Eray Eren1, Qingju Liu2, Hyeongwoo Kim3, Pablo Garrido2, Abeer Alwan1
1Dept. of Electrical and Computer Engineering, University of California, Los Angeles, USA
2Flawless AI, USA
3Imperial College London, UK
Accepted to Interspeech 2025
Prosody conveys rich emotional and semantic information about the speech signal as well as individual idiosyncrasies. We propose a stand-alone model that maps text-to-prosodic features such as F0 and energy and can be used in downstream tasks such as TTS. The ProMode encoder takes as input acoustic features and time-aligned textual content, both are partially masked, and obtains a fixed-length latent prosodic embedding. The decoder predicts acoustics in the masked region using both the encoded prosody input and unmasked textual content. Trained on the GigaSpeech dataset, we compare our method with state-of-the-art style encoders. For F0 and energy predictions, we show consistent improvements for our model at various levels of granularity. We also integrate these predicted prosodic features into a TTS system and conduct perceptual tests, which show higher prosody preference compared to the baselines, demonstrating the model's potential in tasks where prosody modeling is important.
Figure 1: ProMode Diagram.
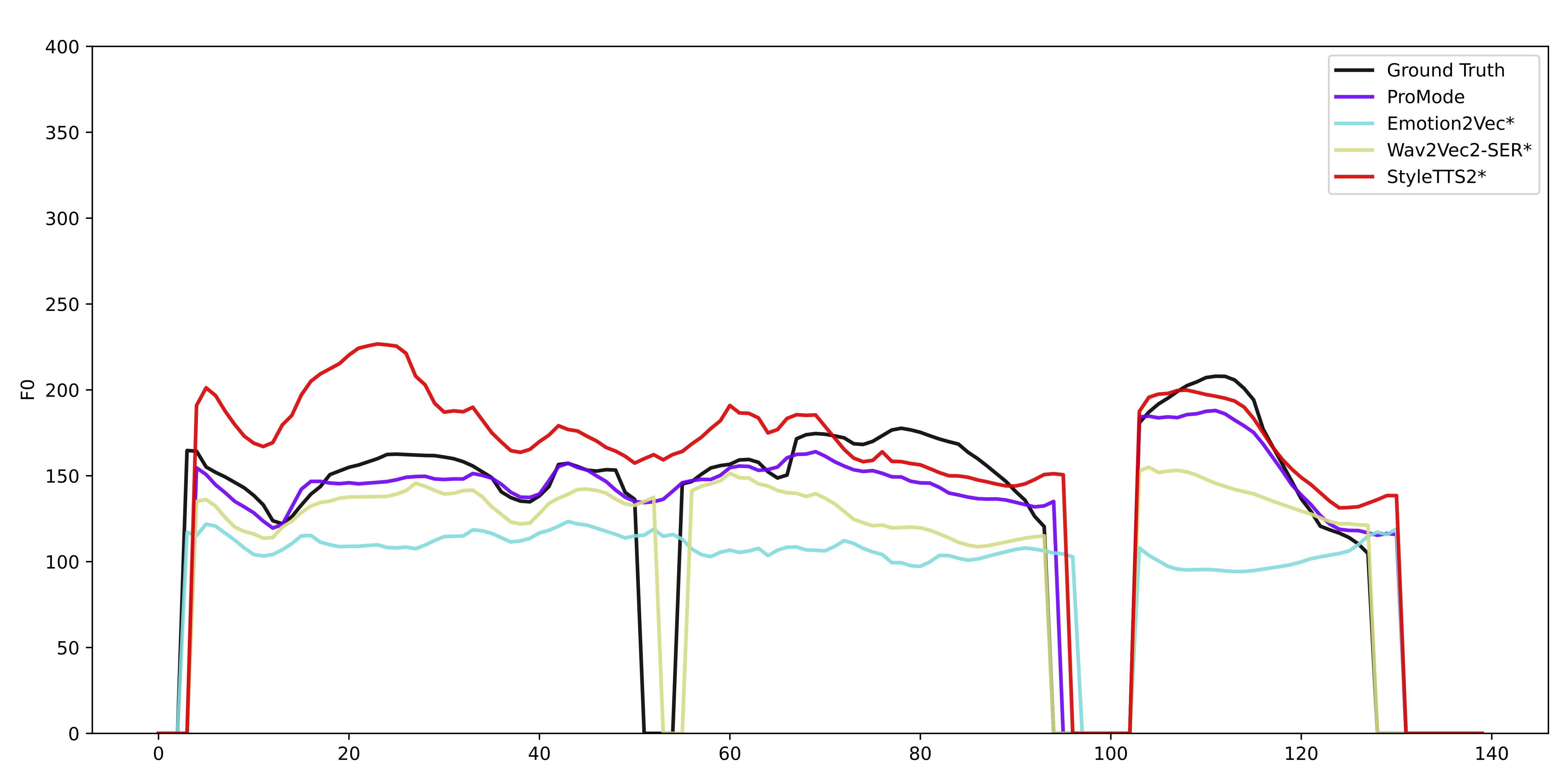
Figure 2: F0 prediction comparison across different models.
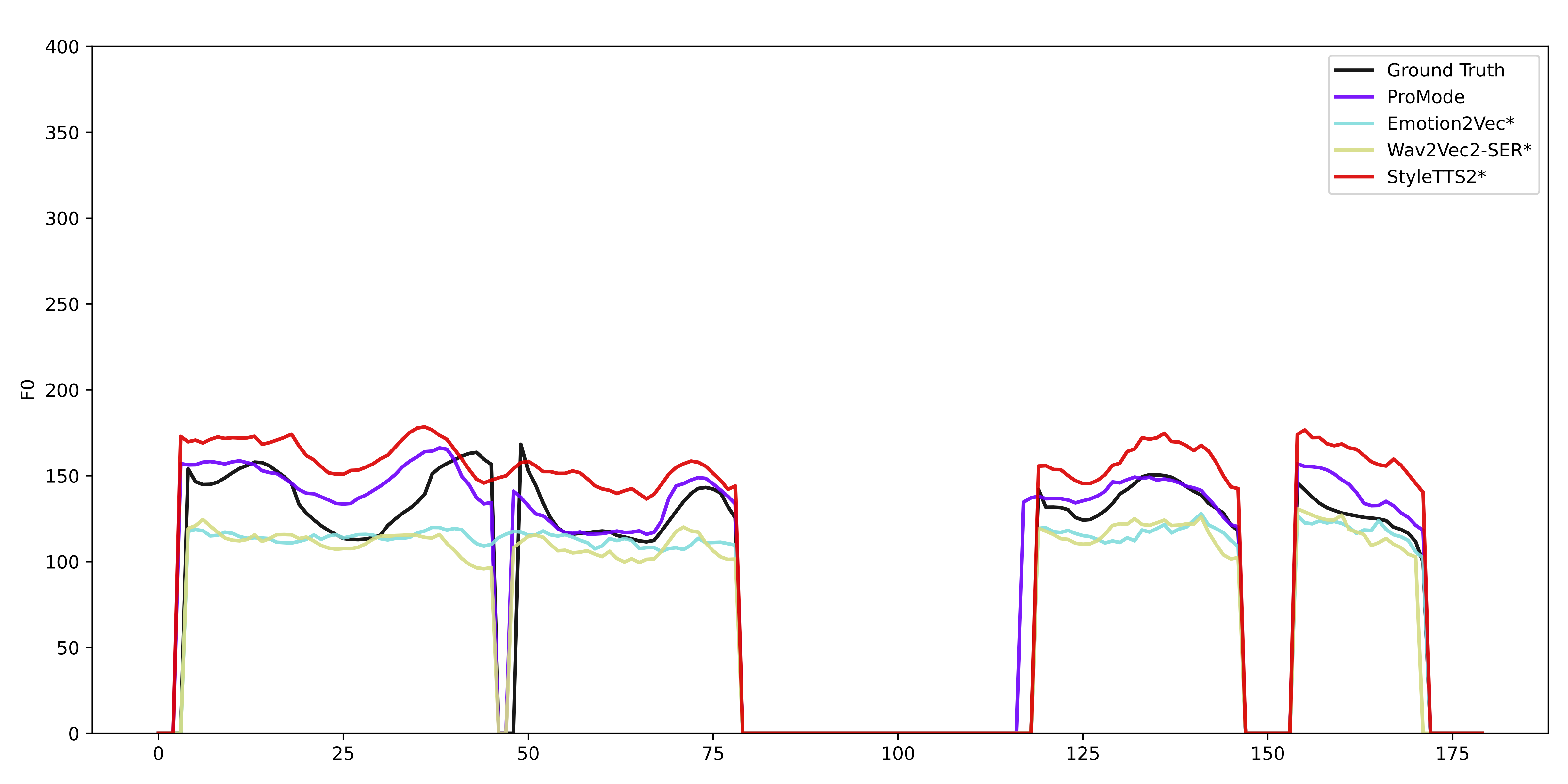
Figure 3: F0 prediction comparison across different models.
We compare our model with state-of-the-art style encoders for F0 prediction on prosody continuation using a reference prosody.
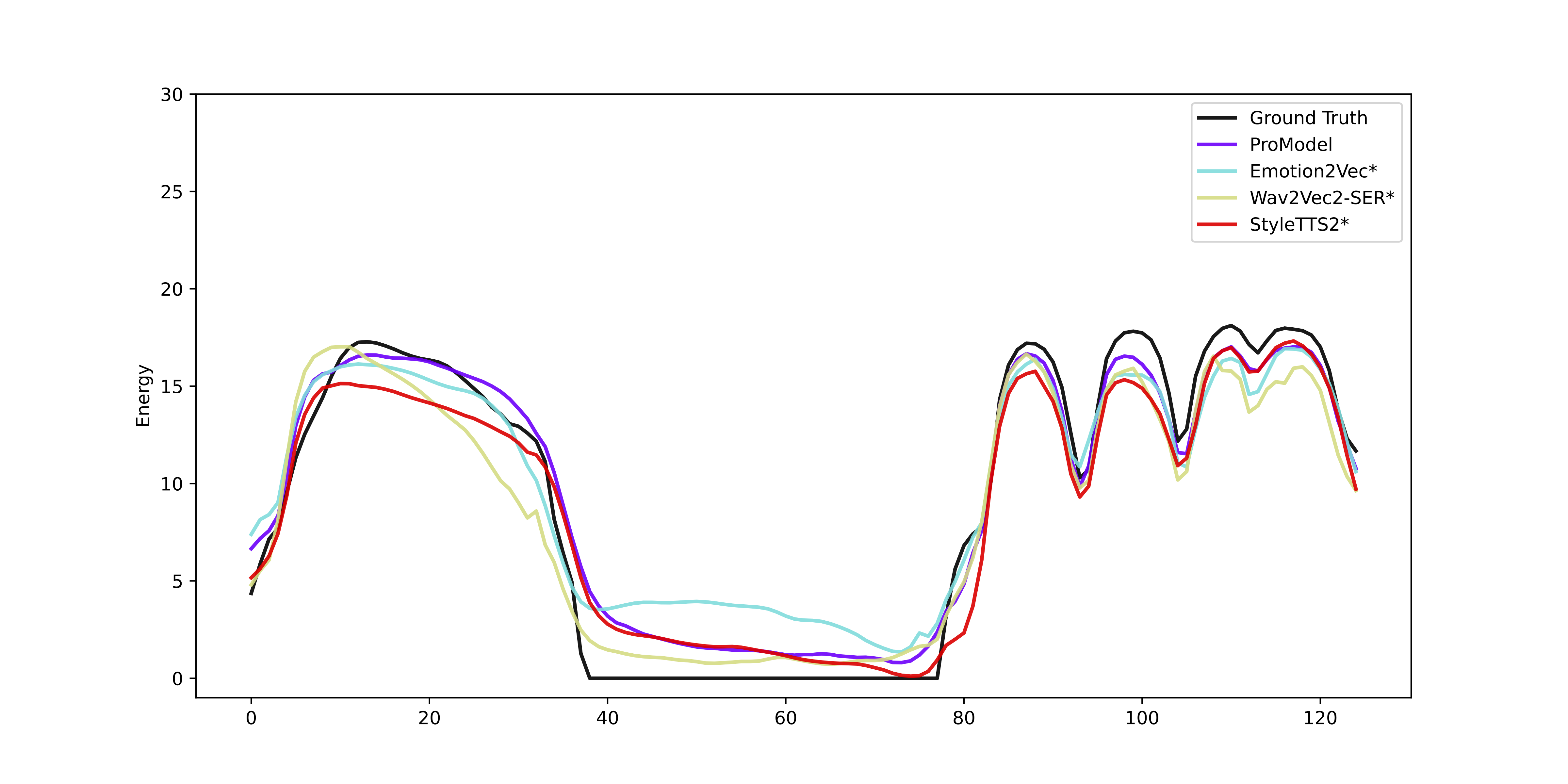
Figure 4: Energy prediction comparison across different models.
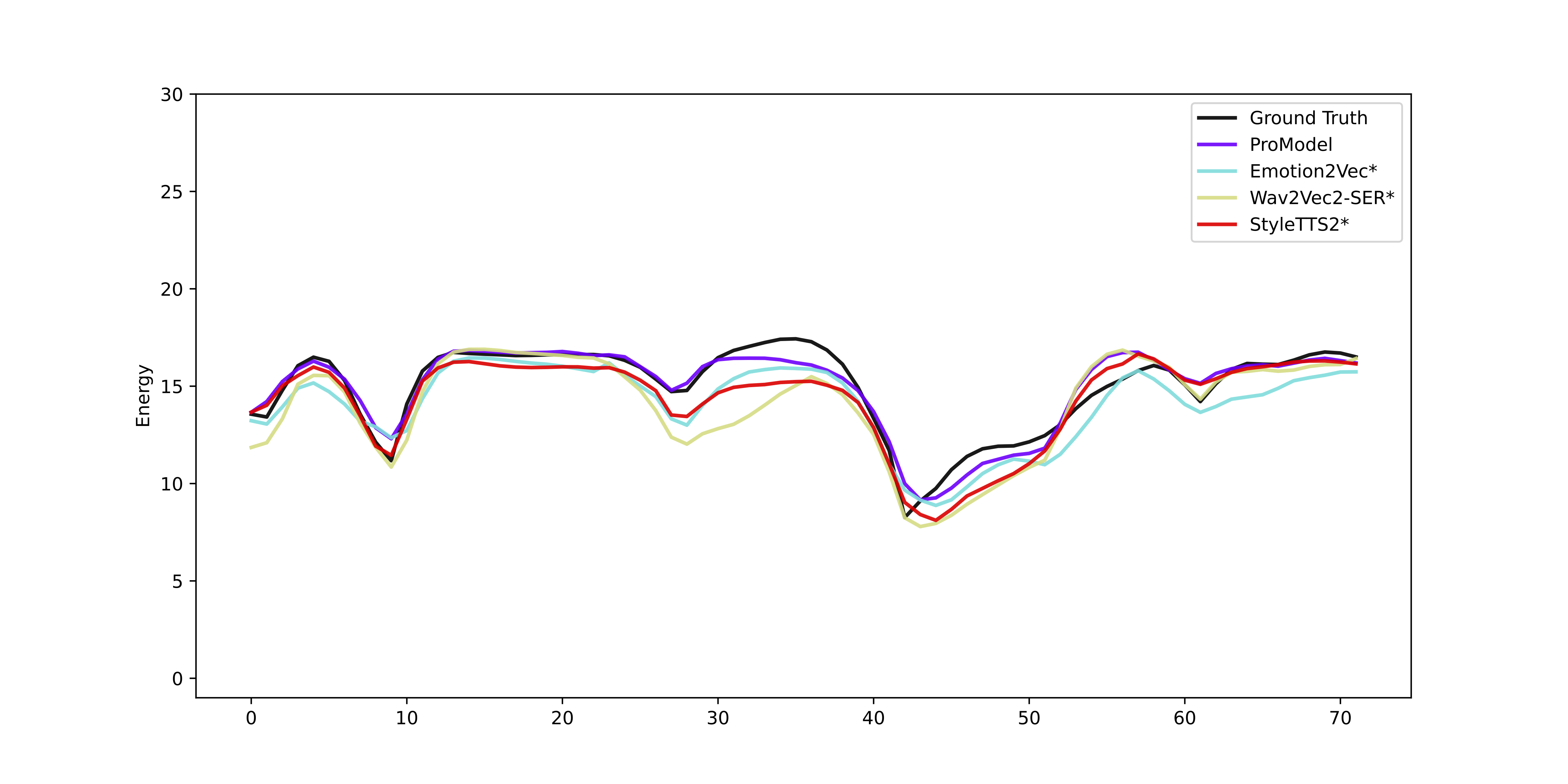
Figure 5: Energy prediction comparison across different models.
We compare our model with state-of-the-art style encoders for energy prediction on prosody continuation using a reference prosody. Energy values are shown in logarithmic (log2) scale, and the values are shifted to start from 0.
Reference:
Ground Truth:
ProMode (Ours)
FluentSpeech
Wav2Vec2-SER*
StyleTTS2*
Emotion2Vec*
Text: "Rorty suggests that we allow our political strategy to reflect the common values of the people that make up the culture."
Reference:
Ground Truth:
ProMode (Ours)
FluentSpeech
Wav2Vec2-SER*
StyleTTS2*
Emotion2Vec*
Text: "She's always expected to hang out and be nice to industry people."
Reference:
Ground Truth:
ProMode (Ours)
FluentSpeech
Wav2Vec2-SER*
StyleTTS2*
Emotion2Vec*
Text: "And that is so key for children to understand math concepts."
Reference:
Ground Truth:
ProMode (Ours)
FluentSpeech
Wav2Vec2-SER*
StyleTTS2*
Emotion2Vec*
Text: "The world on its own unaided by the describing activities of human beings cannot, end quote."
@misc{eren2025promode,
title = {ProMode: A Speech Prosody Model Conditioned on Acoustic and Textual Inputs},
author = {Eray Eren and Qingju Liu and Hyeongwoo Kim and Pablo Garrido and Abeer Alwan},
year = {2025},
eprint = {2508.09389},
archivePrefix = {arXiv},
primaryClass = {eess.AS}
}